Attention mechanisms have transformed the landscape of machine learning, particularly in fields like natural language processing (NLP) and computer vision. The attention mechanism introduced by Bahdanau et al. in 2014 marked a pivotal advancement in machine learning, particularly for sequence modeling tasks like neural machine translation (NMT). Since then, various attention mechanisms have been proposed, each building upon or innovating over its predecessors to address limitations such as computational efficiency, scalability, or the ability to capture complex relationships. These mechanisms have evolved to tackle increasingly complex tasks, from translating languages to processing long documents and images. In this blog, we’ll take a chronological journey through the major attention mechanisms, starting with the groundbreaking work of Bahdanau et al., and highlight how each innovation built upon its predecessors to push the boundaries of what’s possible in AI.
1. Bahdanau Attention (Additive Attention, 2014)
Paper: “Neural Machine Translation by Jointly Learning to Align and Translate” by Bahdanau et al. (2014)
Description:
In 2014, Dzmitry Bahdanau and colleagues introduced the first attention mechanism in their seminal paper, Neural Machine Translation by Jointly Learning to Align and Translate. Introduced in the context of neural machine translation, Bahdanau attention (also called additive attention) enables a model to focus on relevant parts of the input sequence when generating each output token. It computes a context vector as a weighted sum of encoder hidden states, where weights are determined by an alignment score that measures compatibility between the current decoder state and each encoder state.
Before this, neural machine translation models relied on fixed-length context vectors to encode entire input sequences, which struggled with long sentences. Bahdanau’s attention mechanism changed the game by allowing the model to dynamically focus on relevant parts of the input sequence when generating each output word.
This was a significant departure from fixed-length context vectors in earlier encoder-decoder models, allowing dynamic alignment.
How It Works:
Instead of compressing the input into a single vector, Bahdanau’s approach computes a context vector for each decoding step. It assigns weights to different parts of the input based on their relevance to the current output, creating a “soft alignment” that lets the model prioritize important words.
Formula:
For encoder hidden states h1, h2,…… hn and decoder state st at time step( t ):
- Alignment score:
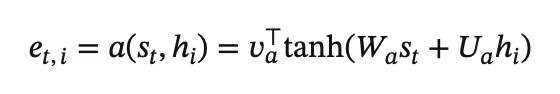
where va, Wa, and Ua are learnable parameters, and a(.) is a feed-forward neural network.
- Attention weights:
- Context vector:
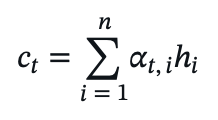
- The context ct is combined with st to produce the output.
Key Innovation:
- Dynamic alignment: Unlike fixed context vectors in traditional encoder-decoder RNNs, Bahdanau attention computes a unique context vector for each decoding step, enabling the model to focus on relevant input tokens.
- Soft alignment: The use of softmax to compute attention weights allows the model to distribute focus across multiple input tokens, capturing complex dependencies.
- Impact: Addressed the bottleneck of fixed-length representations, significantly improving translation quality for long sequences.
2. Luong Attention (Multiplicative Attention, 2015)
Paper: “Effective Approaches to Attention-based Neural Machine Translation” by Luong et al. (2015)
Description:
A year later, Thang Luong and colleagues refined the attention mechanism in their paper, Effective Approaches to Attention-based Neural Machine Translation. Their approach, often called multiplicative or dot-product attention, streamlined Bahdanau’s method to make it more computationally efficient and flexible in order to compute alignment scores.
How It Works:
Luong attention was proposed in the context of NMT and simplifies the alignment process by using a dot-product operation (or its multiple variants like “general” or “local” attention) to measure compatibility between input and output states. The “local” variant further reduces computation by focusing on a subset of input positions, rather than the entire sequence.
Formula:
For encoder hidden states hi and decoder state st:
- Alignment score (three variants):
- Dot-product:
et,i = stThi
- General:
et,i = stT Wahi
where Wa is a learnable weight matrix.
- Local attention: Computes scores only for a window of encoder states around a predicted position pt
.
- Attention weights:
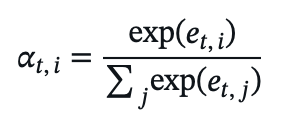
(Sum over all ( j ) for global attention or a window for local attention.)
- Context vector:
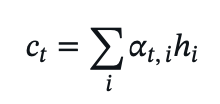
- Key Innovations Over Bahdanau:
- Simpler scoring function: The dot-product and general variants reduce computational complexity by avoiding the feed-forward network used in Bahdanau’s additive attention.
- Local attention: Introduces a mechanism to focus on a subset of input tokens, improving efficiency for long sequences.
- Flexibility: Offers multiple scoring functions (dot, general, local), allowing adaptation to different tasks and architectures.
3. Scaled Dot-Product Attention (Transformer, 2017)
Paper: “Attention is All You Need” by Vaswani et al. (2017)
Description:
In 2017, the Attention is All You Need paper by Vaswani et al. introduced the Transformer model, which brought attention mechanisms to the forefront of machine learning. At its core was the scaled dot-product attention, a refined version of Luong’s multiplicative attention that became the foundation for modern AI architectures.
How It Works:
This mechanism replaces RNNs and uses queries, keys, and values to compute attention scores, allowing the model to weigh the importance of different input tokens. A scaling factor stabilizes training by preventing large values in high-dimensional spaces. Unlike previous RNN-based models, it processes entire sequences in parallel, making it highly efficient. This mechanism is used in both self-attention (within the same sequence) and cross-attention (between encoder and decoder).
Formula:
Given query matrix ( Q ), key matrix ( K ), and value matrix ( V ), with dimension dk:
- Alignment score:
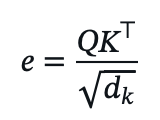
- Attention weights:
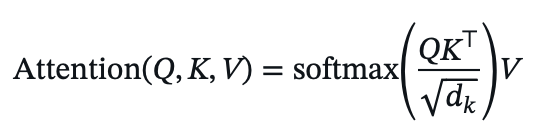
Key Innovations Over Luong:
- Scaling factor: The
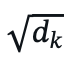
term prevents large dot-product values in high-dimensional spaces, stabilizing gradients during training.
- Parallelization: Unlike RNN-based attention (Bahdanau, Luong), scaled dot-product attention operates on entire sequences simultaneously, enabling efficient GPU computation.
- Self-attention: Extends attention to model relationships within a single sequence, eliminating the need for separate encoder-decoder attention in some cases.
.
4. Multi-Head Attention (Transformer, 2017)
Paper: “Attention is All You Need” by Vaswani et al. (2017)
Description:
Multi-head attention extends scaled dot-product attention by computing multiple attention operations in parallel, each with different learned projections of queries, keys, and values. This allows the model to attend to different subspaces of the input, capturing diverse relationships.
How It Works: Multi-head attention runs several attention operations (or “heads”) in parallel, each with its own set of learned projections. The results are combined to produce a final output, enabling the model to attend to different parts of the input in different ways.
Formula:
For ( h ) attention heads:
- For each head ( i ): headi = Attention(QWiQ, KWiK, VWiV)
where QWiQ, KWiK, VWiV are head-specific projection matrices.
- Combine heads:
MultiHead(Q, K, V) = Concat(head1,………headh) WO
where WO is a projection matrix for the concatenated output.
Key Innovations Over Scaled Dot-Product Attention:
- Multiple subspaces: Each head learns to focus on different features or relationships, improving the model’s ability to capture complex patterns.
- Robustness: Parallel attention heads make the mechanism more expressive and less sensitive to initialization or specific input patterns.
5. Sparse Attention (2020 onwards)
Papers: Examples include “Longformer: The Long-Document Transformer” by Beltagy et al. (2020) and “Big Bird: Transformers for Longer Sequences” by Zaheer et al. (2020)
Description:
By 2020, the quadratic complexity O(n2) of Transformer’s self-attention (which grows with sequence length (n)) became a bottleneck for processing long documents. Sparse attention, introduced in papers like Longformer by Beltagy et al. and Big Bird by Zaheer et al., addressed this by limiting the number of positions each token attends to.
How It Works: Instead of computing attention across all input tokens, sparse attention uses patterns like sliding windows, global tokens, or random connections to focus on a subset of positions. This reduces computational demands while still capturing essential dependencies.
Formula:
Varies by specific mechanism, but for a sliding window attention (e.g., Longformer):
- For each position ( i ), attend only to a fixed window of size ( w ):
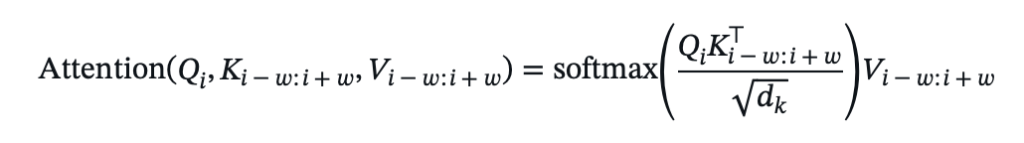
- Some models add global tokens or dilated windows to capture broader dependencies.
Key Innovations Over Multi-Head Attention:
- Efficiency: Reduces computational complexity to O(n) or O(nlog n) by attending to a subset of positions.
- Scalability: Enables Transformers to handle much longer sequences (e.g., thousands of tokens) for tasks like document processing.
- Flexibility: Different sparse patterns (e.g., sliding window, dilated, random) cater to specific use cases, balancing local and global context.
6. Performer Attention (2020)
Paper: “Rethinking Attention with Performers” by Choromanski et al. (2020)
Description:
Also in 2020, Rethinking Attention with Performers by Choromanski et al. introduced a novel approach to achieve linear complexity without relying on sparse patterns. Performer attention approximates the softmax operation in self-attention using kernel-based methods, achieving linear complexity O(n) instead of quadratic.
How It Works: By reformulating the attention computation using random feature maps, Performer approximates the full attention matrix without explicitly computing it. This allows it to scale to very long sequences while maintaining performance close to the original Transformer.
Formula:
Using a kernel approximation, the attention computation is reformulated:
- Standard attention:
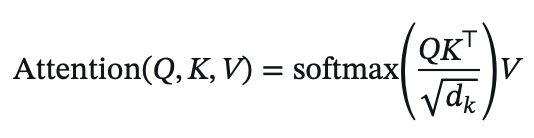
- Performer approximates the softmax kernel using random features ø:
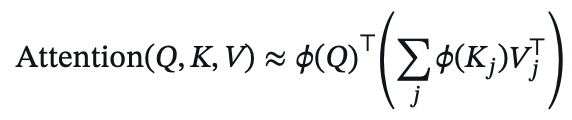
where ø maps queries and keys to a lower-dimensional space.
Key Innovations Over Sparse Attention:
- Linear complexity: Achieves O(n) complexity without relying on predefined sparse patterns, making it more general-purpose.
- Kernel-based approximation: Avoids explicit computation of the full attention matrix, enabling efficient processing of very long sequences.
- Preserves expressiveness: Maintains comparable performance to full attention by carefully designed feature mappings.
7. Linformer Attention (2020)
Paper: “Linformer: Self-Attention with Linear Complexity” by Wang et al. (2020)
Description:
The Linformer paper by Wang et al. in 2020 took a different approach to efficiency. Linformer reduced the memory and computational complexity of self-attention by projecting the key and value matrices to a lower-dimensional space. This low-rank approximation assumes that the attention matrix has a low-rank structure, enabling linear complexity.
How It Works: Instead of working with the full key and value matrices, Linformer projects them to a smaller dimension before computing attention. This low-rank approximation maintains performance while making the model more resource-efficient.
Formula:
- Project keys and values to dimension k << n:
K’ = K E, V’ = V E
where
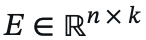
is a projection matrix.
- Compute attention:
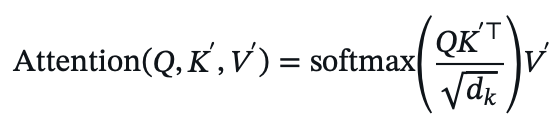
Key Innovations Over Performer:
- Low-rank assumption: Explicitly reduces the dimensionality of keys and values, simplifying the attention computation.
- Memory efficiency: Significantly reduces memory usage, making it practical for resource-constrained environments.
- Simplicity: The projection-based approach is straightforward to implement and integrate into existing Transformer architectures.
8. Swin Transformer Attention (2021)
Paper: “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows” by Liu et al. (2021)
Description:
In 2021, the Swin Transformer by Liu et al. adapted attention mechanisms for computer vision tasks, introducing a hierarchical approach tailored to the 2D structure of images. It became a game-changer for vision applications, rivaling convolutional neural networks. This is a form of sparse attention tailored for 2D data.
How It Works: Swin Transformer divides images into non-overlapping windows and computes attention within each window. Subsequent layers use shifted windows to allow cross-window interactions, capturing both local and global features across multiple scales.
Formula:
- For a window of size MxM, compute attention within each window:
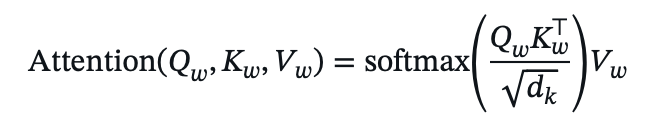
- In shifted window layers, adjust window boundaries to include cross-window connections.
Key Innovations Over Linformer:
- Hierarchical structure: Processes images at multiple scales, mimicking convolutional neural networks’ ability to capture local and global features.
- Shifted windows: Enables cross-window information flow, addressing the limitation of isolated windows in sparse attention.
- Vision-specific: Adapts attention to the 2D structure of images, outperforming standard Transformers on vision tasks.
Summary of Evolution
- Bahdanau (2014) introduced dynamic, soft alignment for sequence modeling, solving the fixed-context bottleneck.
- Luong (2015) simplified scoring and introduced local attention for efficiency.
- Scaled Dot-Product (2017) enabled parallelization and introduced scaling for numerical stability, forming the Transformer’s core.
- Multi-Head (2017) enhanced expressiveness by capturing diverse relationships.
- Sparse Attention (2020) addressed quadratic complexity for long sequences with structured sparsity.
- Performer (2020) achieved linear complexity via kernel approximations, maintaining generality.
- Linformer (2020) used low-rank projections for memory efficiency.
- Swin Transformer (2021) adapted attention for hierarchical vision tasks with shifted windows.
Each mechanism builds on its predecessors by improving efficiency, scalability, or task-specific performance, with the Transformer’s scaled dot-product and multi-head attention serving as the foundation for most modern advancements.